Every marketer wants their content to rank well in search engines, which is why we invest so much time into our websites’ Search Engine Optimization (SEO).
While many aspects of SEO are pretty straightforward — like headings, meta descriptions, and link building — other aspects of SEO can be a bit trickier. But that doesn’t mean you can afford to ignore them.
One of these trickier elements is canonicalization — and it can play an important role in how search engines evaluate the quality of your pages.

What is a Canonical Tag?
Sometimes referred to as “rel=canonical,” canonical tags tell search engines that a given URL is the master copy or authoritative source for a piece of content. If there are multiple versions of the same piece of content at different URLs, the canonical tag informs search engines which one is the primary source. The canonical tag appears in the HTML head of your page.
You can think of canonical tags as the technical SEO version of including a citation, as it gives credit to the original material and prevents duplicate content penalties.
On the surface, the concept of using canonical tags to avoid duplicate content issues might seem pretty straightforward. After all, even middle schoolers are taught that you can’t just copy and paste content from a website and call it your own. But leaving duplicate content issues up to chance shouldn’t be an option. Your SEO strategy should include a plan for managing potential duplicate content issues with canonical tags.
Duplicate content can create problems when you consider that search engines and humans look at content in very different ways. For example, we, humans, may think of http://www.hubspot.com and http://hubspot.com as the exact same page. After all, we built it as a singular page, not two separate pages, and the difference in the URL is just a matter of how someone arrives at the page.
Even though users on your site know that the page is the same even if it’s loaded under one of these conditions, search engines perceive a distinct URL for each version, and therefore think that they are each unique pages. As a result, we’re in a tough spot where there are several pages that have the exact same content. If we look at these pages from Google’s perspective, we’ve got a case of plagiarism.
Much like your high school English teacher, Google frowns on plagiarism, and your SEO will be negatively impacted due to duplicate content.
Luckily, canonicalization offers a solution to this.
When are Canonical URLs necessary?
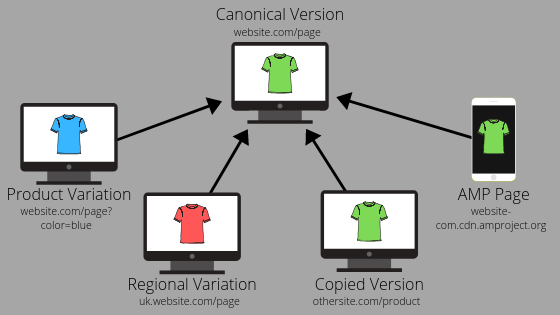
The previous example of the same content being at https://www.hubspot.com and https://hubspot.com is just one of the situations in which it is important to include a canonical URL. Each of the following situations is a commonly occurring instance of when you’ll want to make sure you’ve added a canonical URL:
URLs that Identify Variations of the Same Product
Especially on e-commerce platforms, it’s quite common for URLs to adjust depending upon the specifics of the product that a customer is looking at. For example, let’s say you’re selling dog toys, and have a popular chew toy that comes in three separate sizes and has color options as well. The main page for that product may be www.example.com/product, but you likely also have pages URLs like www.example.com/product?size=large&color=blue.
Mobile-Specific URLs, Such as AMP Pages or a Mobile-Specific Subdomain
Creating content with mobile in mind is a marketing must — just be sure to remember to set your canonical URLs when you have pages that are specific to mobile but have the same content as a page on the desktop version of your website. For AMP pages specifically, Google also provides detailed guidelines on how to correctly differentiate your Accelerated Mobile Page from your standard webpage.
Region or Country-Specific URLs
Geotargeting is another great way to cater your content to your viewers based upon where they live. If you do this by adding a regional slug or using a regional subdomain (e.g. https://www.example.com/fi/page or https://de.example.com), you’ll want to make sure these region-specific pages point back to the master version of the page. It’s important to note that if you’re translating your page (for example you have the master version in English and have another version that’s entirely in Mandarin), this wouldn’t be a case of duplicate content. When it comes to region-specific content, you’ll want to include the canonical tag if most of the on-page content is the same and in the same language.
Self-Referential URLs
Most CMS platforms do this automatically, but it’s important to not overlook it. When you create a page, you can set it as its own canonical URL. This is known as a “self-referential canonical URL.” The usefulness of self-referential canonical tags has been widely debated until recently when Google confirmed that this can help your pages perform well in search results.
How to Set the Canonical URL for Your Page
When it comes to setting Canonical URLs for your pages, there are a few different approaches you can take. Each approach has its own benefits and disadvantages, and some may make more sense for you than others depending upon your overall web strategy. That being said, there isn’t one method that’s uniformly “better” or more SEO-friendly than the others. When it comes down to it, each method has its own situation where it’ll be most appropriate, and the bottom line is that across the board it’s better to have a canonical URL set than to not.
Specifying the Preferred Domain
One option for setting canonical URLs requires using Google Search Console to specify your preferred canonical domain. The primary benefit of this approach is that it is quick and easy to implement, and is ideal for sites that have the same content living at the same URL paths but at different domains. For example, you may have a main office and a branch office that have the same “About Us” page at two separate domains. With this method, you can set www.mainoffice.com/about as the canonical variation of www.branchoffice.com/about without making any in-depth adjustments to your website.
The downside to this approach is that specifying the preferred domain in Google Search Console is only going to correctly set the canonical variation for Google, and not for other search engines. Additionally, your URL paths have to be identical for this to work. This method can correctly identify the canonical version for two pages ending in “/about”, but if one is “/about” and the other is “/about-us/,” this method won’t work.
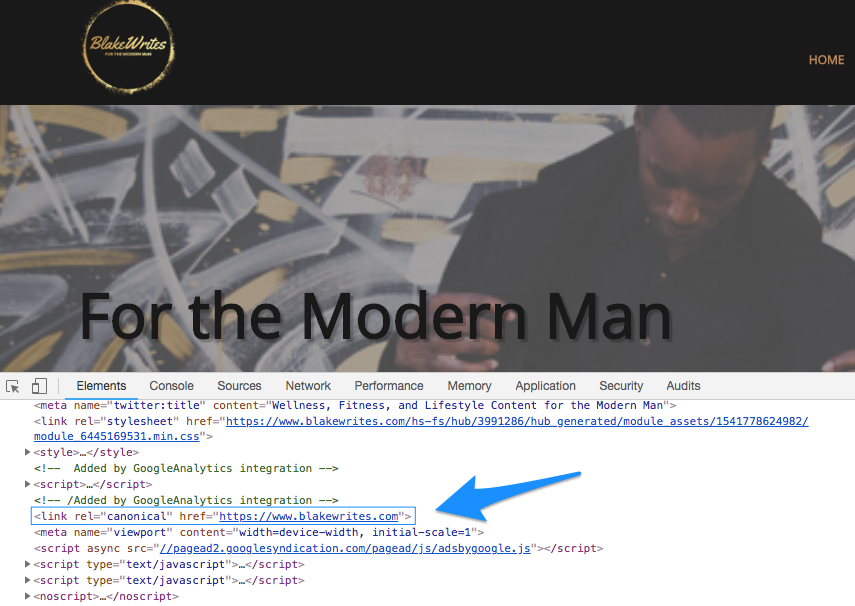
Using rel=”canonical” tag
Perhaps the most common option for specifying the canonical version of a page is to use the rel=”canonical” tag. With this approach, you’re adding metadata to the page head and specifying the appropriate URL to be used as the canonical address. This tag is added within the page’s head tags (not to be confused with the page’s header) and is formatted as: .
The primary benefit to this approach is that it can identify the canonical URL for an infinite number of pages, and you don’t have to worry about specific URL paths like you do with the preferred domain method. Plus, many content management systems, including HubSpot, will automatically set and update the canonical tag in your pages’ metadata.
As far as drawbacks go, this approach can add to the size of your page, which may affect loading speeds on weaker internet connections. Additionally, if your CMS doesn’t automatically update this tag, it can be difficult to maintain accurate canonical tags if your website’s URLs are updated with much frequency.
Using rel=canonical HTTP header
Functioning similarly to the rel=”canonical” tag, you can set a canonical link in your HTTP header response to identify the correct canonical version of your content. This method is particularly useful if you have PDFs or other non-HTML content on your website that you need to correctly identify, as the tag metadata only works with HTML pages.
Like the canonical method, this approach can be used to map an infinite number of pages, but because it isn’t loaded onto the page as metadata, it doesn’t increase the size of your page.
The challenge with this approach is that it can be a bit more difficult to set up correctly than the other approaches, and it can also be difficult to maintain for very large websites or sites where URLs change somewhat frequently.
301 Redirects
A 301 redirect is a permanent redirect that forwards one URL to another. For example, you may type “example.com” into your browser and automatically be redirected to “www.example.com.” 301 redirects tell Googlebot and other search engine crawlers that the URL to which a page gets forwarded needs to be considered the canonical variation.
It’s best to use this approach only when you’re deprecating one version of a page for another or when you’re forwarding the root domain to a subdomain. Using it in other situations can create issues for the clarity of your sitemap, and can also cause issues if you decide to reuse a URL for different content.
Canonicalization is Key
Setting the canonical URL for your pages is a great way to ensure that search engines and visitors alike understand where your content is coming from, and that your website is performing as well as possible in search rankings. By leveraging canonicalization, you can indicate the structure and organization of your content in a way that shows that it is as unique as your business and your customers.

![]()