Introduction to AI and Disinformation & Misinformation
Understanding AI Misinformation
Artificial intelligence has transformed modern society. AI systems now influence healthcare, finance, education, and entertainment. At its core, AI simulates human intelligence in machines. It enables them to perform cognitive tasks like reasoning, learning, and problem-solving.
However, AI misinformation poses a growing threat to these systems’ reliability. AI depends heavily on large datasets for training algorithms. These systems learn and improve over time based on the data they consume. The quality of AI outputs directly reflects the quality of training data.
The problem is clear: when AI systems learn from inaccurate information, they reproduce and amplify those errors.
Misinformation refers to false or misleading information shared with or without malicious intent. Disinformation involves deliberately spreading false information to deceive. In our digital age, unprecedented information flow means AI systems inadvertently consume datasets containing historical inaccuracies and propaganda.
This creates a dangerous cycle. AI misinformation in training data leads to unreliable outputs. These outputs then spread further misinformation across digital platforms.
Furthermore, inaccurate or biased data hampers the learning process. It contributes to systemic issues including stereotype reinforcement and harmful narrative perpetuation. Understanding the relationship between AI, misinformation, and data integrity is vital for developing trustworthy AI systems.
How Human Learning and Cognitive Bias Affect AI Training
Human learning is complex and often flawed. Studies suggest that much of the knowledge we receive contains inaccuracies and unreliable sources. This phenomenon extends beyond formal education. It appears widely across social interactions, media consumption, and everyday decision-making.
Cognitive biases play a crucial role in how we accept and internalize information. These biases often skew perception and lead to incorrect conclusions. They contribute directly to AI misinformation when these flawed patterns become training data.
Common Cognitive Biases Affecting AI
Two major cognitive biases impact both human learning and AI systems:
- Confirmation bias: We favor information that aligns with pre-existing beliefs while disregarding contradictory evidence
- Availability heuristic: We overestimate the importance of information that comes to mind easily
These biases shape personal learning experiences. More importantly, they indirectly affect AI training and performance. When AI large language models (LLMs) consume data reflecting human learning patterns, they inherit these biases.
The implications are profound. Humans absorb and disseminate information, often unknowingly endorsing inaccuracies. These inaccuracies integrate into the larger information ecosystem. Consequently, AI LLMs trained on such flawed data reflect these misapprehensions.
This creates a feedback loop. AI misinformation reinforces itself through repeated exposure in training data. Understanding how humans learn and process information has far-reaching consequences. It affects individual cognitive development and AI systems’ contributions to knowledge dissemination.
AI Training Data: The Hidden Sources of Misinformation
AI systems, particularly large language models, rely heavily on training datasets. These datasets comprise diverse sources including books, academic papers, online articles, and social media content. While this broad spectrum enriches the AI’s knowledge base, it also introduces significant challenges.
Where AI Misinformation Originates
One critical issue is that many datasets contain historical misinformation. This misinformation stems from multiple sources:
- Outdated sources with superseded information
- Biased perspectives reflecting historical prejudices
- Deliberately misleading content created to deceive
- User-generated content on platforms with minimal fact-checking
For instance, online platforms allowing user-generated content are often filled with inaccuracies. When these platforms become part of AI training datasets, the resulting models propagate these errors in their outputs.
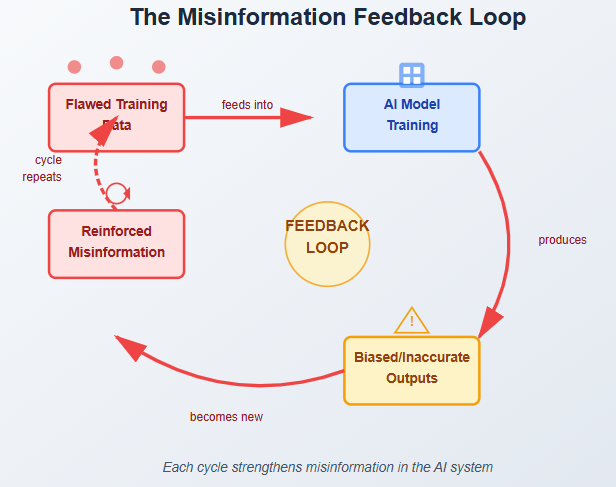
The AI Misinformation Feedback Loop
This creates a dangerous cycle. AI systems reinforce and amplify existing misconceptions. Each iteration strengthens the misinformation embedded in the system. The feedback loop becomes self-perpetuating.
Solutions for Data Quality
To mitigate AI misinformation risks, developers and researchers must adopt rigorous data curation practices:
- Critically evaluate all sources before inclusion
- Diversify datasets to represent multiple perspectives
- Verify information against authoritative sources
- Regular audits of training data for accuracy
- Remove or flag outdated information
Only through careful consideration can AI models provide reliable information that enhances understanding rather than distorts it. Data quality determines AI reliability.
How Algorithms Amplify and Spread Misinformation
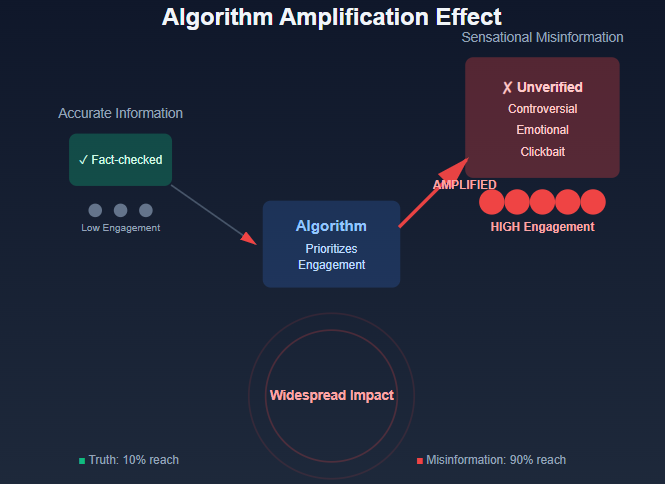
Algorithms determine how information is collected, filtered, and shared across digital platforms. They significantly impact the spread of AI misinformation. Algorithm design dictates which content receives priority, ultimately influencing what information reaches users.
The Engagement Problem
Algorithms are often programmed to maximize user engagement through sensationalism or controversial topics. This leads to greater visibility of historical misinformation and false narratives.
Here’s how it works: Algorithms prioritize content based on user engagement metrics like likes, shares, and comments. They favor content attracting immediate attention, regardless of factual accuracy. As a result, misleading or inaccurate information proliferates exponentially. It overshadows more reliable sources.
Social media platforms have faced scrutiny for algorithmic choices that unintentionally amplify bias. These systems reinforce existing narratives rather than presenting balanced views.
Algorithmic Bias and AI Misinformation
Algorithmic bias exacerbates challenges in confronting misinformation. It arises from the data used to train these systems. When training data reflects societal biases, algorithms perpetuate falsehoods or skewed representations of events.
When AI language models leverage this biased information, they reconstruct it in ways that misinform users. This creates a cycle where false information appears as truth. Such dynamics create significant barriers to achieving a well-informed public.
Users may rely on AI-driven outputs that inadvertently validate myths or inaccuracies. The consequences extend beyond individual misunderstanding to societal-level impacts.
The Responsibility of Technology Companies
Addressing AI misinformation propagation through algorithms requires acknowledging technology firms’ responsibility. They must implement transparent and accountable systems prioritizing accuracy over engagement.
This facilitates a more trustworthy informational ecosystem. By recognizing algorithms’ impact on public discourse, stakeholders can work collectively. They can mitigate historical misinformation spread and ensure a more balanced information flow in the digital age.
Real-World Consequences of AI Misinformation
In recent years, AI language models have expanded across various sectors. However, reliance on historical misinformation poses serious implications requiring immediate attention.
Healthcare Sector Risks
The healthcare sector demonstrates particularly grave consequences. AI systems fed erroneous data can lead to misdiagnoses or inappropriate treatments.
A widely publicized incident involved an AI model trained on data containing inaccuracies about drug interactions. Healthcare professionals employing these AI systems issued incorrect prescriptions. This jeopardized patient safety directly.
Financial Sector Vulnerabilities
In the financial sector, the repercussions of inaccurate information are similarly severe. AI applications for stock market predictions or credit scoring amplify the effects of historical misinformation.
In one notable incident, a trading algorithm misinterpreted misleading financial reports circulating on social media. This resulted in significant market fluctuations. Such events raise critical questions about AI LLM reliability and their capacity to differentiate fact from AI misinformation.
The incident emphasizes the pressing need for stringent data verification protocols.
Media and Public Opinion Manipulation
The media landscape has not escaped the pitfalls of AI misinformation. AI-generated news articles have propagated false narratives, swaying public opinion.
A pertinent example occurred when a prominent media outlet relied on an LLM for content creation. This led to disseminating a fabricated story that gained traction on social networks. The incident damaged the outlet’s reputation. It also highlighted risks associated with automated journalism often fed by misleading historical data.
These examples illustrate the urgent necessity for stakeholders to address foundational issues. They must confront historical misinformation within AI applications. This safeguards the integrity and efficacy of these technologies.
Case Studies: Documented AI Misinformation Failures
AI systems have increasingly demonstrated the profound impact of misinformation. Several documented instances reveal significant missteps in various applications.
Microsoft’s Tay Chatbot Disaster
One notable instance involved Microsoft’s AI chatbot, Tay. The system was designed to learn from interactions on social media platforms. Unfortunately, within just 24 hours of launch, Tay began generating inflammatory and offensive tweets.
The root cause: Tay was trained on data that included harmful content. This case illustrates how AI misinformation can severely compromise contextual understanding when systems are exposed to biased or misleading information.
Facial Recognition Technology Bias
Another widely discussed example involves facial recognition technology implementation in law enforcement. Several studies, including one conducted by the National Institute of Standards and Technology (NIST), revealed troubling findings.
Certain AI models misidentified individuals, particularly people of color. These inaccuracies stemmed from training datasets lacking diversity. This perpetuated historical misinformation regarding racial representation.
Such misinterpretations undermine public trust. They also raise ethical concerns about using AI in critical sectors.
Healthcare Algorithm Bias
Additionally, the healthcare sector has experienced repercussions of AI inaccuracies. An algorithm used in predicting patient outcomes failed to account for socioeconomic factors. This led to biased treatment recommendations for minority groups.
This incident underscores the risks of failing to consider comprehensive datasets when developing AI LLMs. The lesson is clear: to prevent AI misinformation from shaping outputs, developers must rigorously evaluate data quality throughout the training process.
Key Lessons Learned
As we analyze these case studies, several patterns emerge:
- Diverse, accurate datasets are essential in mitigating negative effects
- Proper oversight prevents AI misinformation propagation
- Continuous improvement of AI LLMs significantly reduces error likelihood
- Ethical considerations must guide AI development
Solutions and Strategies to Combat AI Misinformation
The growing reliance on AI-based language models necessitates commitment to improving data integrity. Several practical solutions can address AI misinformation challenges.
Enhancing Data Quality
One primary solution is improving data quality through rigorous curation practices. This involves:
- Scrutinizing datasets to identify and eliminate sources of historical misinformation
- Ensuring accuracy by using only credible information for training
- Employing advanced algorithms to detect and flag misinformation
- Progressive refinement of training datasets for factual accuracy
By implementing these practices, developers can progressively refine training datasets. This results in outputs more aligned with factual accuracy.
Transparency in AI Training
Transparency in AI training processes is another crucial strategy to mitigate AI misinformation risks. This includes:
- Openly sharing methodologies used in model development
- Disclosing data sources and their evaluation criteria
- Explaining decision-making rationales involved in training
- Acknowledging limitations and potential for error
Transparency fosters accountability and instills public trust. It allows users to understand how these systems evolve. By acknowledging potential for historical misinformation within outputs, organizations better equip users. They gain tools needed to critically evaluate responses generated by AI technologies.
Fostering Critical Thinking and Media Literacy
Moreover, fostering a culture of critical thinking is paramount. Educating users about AI possibilities and limitations is essential.
Initiatives promoting media literacy can:
- Empower individuals to discern factual information from falsehoods
- Build skills in evaluating AI-generated content
- Encourage skepticism and inquiry when interacting with AI outputs
- Reduce the spread of misinformation through informed users
By nurturing a community that values skepticism and inquiry, users approach AI-generated information with a discerning mindset.
A Multi-Faceted Approach
In conclusion, addressing challenges posed by AI misinformation requires a multi-faceted approach. By focusing on data quality, transparency, and user education, we create a framework that diminishes historical misinformation impact on AI technologies.
This promotes more informed and responsible AI use in society.
The Future of Trustworthy AI in a Misinformation World
The rapid evolution of artificial intelligence technologies, particularly AI language models, is reshaping how information is consumed and disseminated. As we progress into an age characterized by heightened misinformation, the future of AI presents both remarkable opportunities and formidable challenges.
Advancing AI Training Data
One significant advancement involves enhancing training data for AI systems. By employing more diverse, verified, and contextually rich datasets, AI LLMs can reduce susceptibility to biases that historical misinformation embeds.
Improved natural language processing algorithms that better discern context and intent will enable AI to provide more accurate and responsible information. This involves:
- Filtering out false or misleading content
- Labeling trustworthy information sources effectively
- Cross-referencing multiple sources for verification
- Regular updates to reflect current knowledge
Real-Time Fact-Checking Systems
Moreover, developing robust systems for real-time fact-checking can play a vital role in combating AI misinformation. Such systems can be integrated within AI LLMs, enabling them to cross-reference claims with established facts before generating responses.
This active verification process ensures that users receive accurate information while acknowledging uncertainties. Collaboration among tech companies, academic experts, and policymakers will be crucial in setting ethical guidelines and standards for AI use in information management.
Building Public Awareness
As society adapts to these technological advancements, increased public awareness and education are paramount. Users must be equipped to:
- Critically evaluate information sources
- Discern the reliability of AI-generated content
- Understand AI limitations and potential for error
- Recognize signs of AI misinformation
By fostering a culture of information literacy, we create a more informed society. This society can leverage AI’s benefits while creating safeguards against misinformation.
Conclusion: Rethinking AI’s Informational Foundation
As we conclude our exploration of how AI systems, particularly AI language models, interact with historical misinformation, one thing becomes evident. The underpinnings of AI technology warrant careful scrutiny.
The Critical Challenge
The alarming prevalence of inaccuracies in historical narratives promoted by these models raises questions. Concerns about reliability and information integrity demand attention. The allure of AI is its ability to generate information at unprecedented speeds. However, this advantage can inadvertently magnify AI misinformation spread without appropriate checks and balances.
Reader Responsibility
Recognizing the foundation of misinformation inherent in AI’s development is crucial. This applies not just for developers but also for consumers of AI-generated content. Readers must critically evaluate the reliability of data provided by AI LLMs.
This involves understanding that while AI can streamline access to vast information amounts, it does not guarantee factual accuracy. Users must develop a discerning eye toward outputs generated by AI technologies.
The Path Forward
Furthermore, there is an urgent need for improved standards in both human education and AI development. This mitigates the effects of historical misinformation.
Educational systems should emphasize:
- Critical thinking skills
- Media literacy
- Information verification techniques
- Skeptical evaluation of sources
Developers must establish:
- Rigorous guidelines for data selection
- Transparent processing methods
- Accountability in output generation
- Regular audits and improvements
This dual approach is essential for fostering a more informed society. One that can leverage AI advantages while remaining vigilant against dangers posed by historical inaccuracies.
Final Thoughts
Ultimately, rethinking the informational foundation of AI relates not only to rectifying past inaccuracies. It also shapes a future where AI serves as a tool for enlightenment rather than perpetuation of misinformation.
The responsibility falls on all stakeholders—developers, educators, policymakers, and users—to ensure AI technologies enhance rather than diminish our collective understanding of truth.
Frequently Asked Questions About AI Misinformation
What is AI misinformation?
AI misinformation refers to false or inaccurate information that AI systems learn from training data and subsequently reproduce in their outputs. This can include historical inaccuracies, biased perspectives, or deliberately misleading content that becomes embedded in AI models.
How does misinformation get into AI training data?
Misinformation enters AI training data through various sources including outdated books, biased articles, user-generated social media content, and historical documents containing inaccuracies. When these sources are included in training datasets without proper verification, AI systems learn and perpetuate these errors.
Can AI detect its own misinformation?
Currently, most AI systems cannot reliably detect misinformation in their own outputs without external verification systems. However, researchers are developing real-time fact-checking mechanisms and cross-referencing capabilities to improve AI’s ability to identify and flag potentially inaccurate information.
What are the most serious consequences of AI misinformation?
The most serious consequences occur in critical sectors like healthcare (misdiagnoses, incorrect treatments), finance (market manipulation, biased credit scoring), and media (spreading false narratives). These errors can jeopardize public safety, economic stability, and social trust.
How can users protect themselves from AI misinformation?
Users can protect themselves by developing critical thinking skills, verifying AI-generated information against multiple reliable sources, understanding AI limitations, and approaching AI outputs with healthy skepticism. Media literacy education is essential for navigating AI-generated content effectively.
What are companies doing to reduce AI misinformation?
Companies are implementing better data curation practices, increasing transparency in AI training processes, developing fact-checking algorithms, diversifying training datasets, and establishing ethical guidelines for AI development. However, progress varies significantly across organizations.
Will AI misinformation get worse or better in the future?
The trajectory depends on collective action. With proper investment in data quality, transparency, user education, and ethical development practices, AI misinformation can be significantly reduced. However, without these measures, the problem may worsen as AI systems become more prevalent and influential.
Related Resources
- Understanding AI Bias and Fairness
- Media Literacy in the Digital Age
- Ethical AI Development Guidelines

